LLMs are super useful for learning and building things, and we are barely using them to their full potential.
Below is my collection of techniques and tools I use to get way more out of LLMs.
Using LLMs to improve your understanding #
Learn different thinking/analysis styles #
You can use LLMs to explain how different skill levels would analyze/talk about a concept (e.g. analyze e4 e5 nf3 nc6 from the perspective of a beginner, novice, expert, national master, grand master, world champion). This will give you different useful examples of how you can think/analyze something. You can also find terms that higher-skilled people use to think/analyze, which will show you what concepts to pay attention to, or powerful concepts that you may be dismissing.



IQ bell curve meme #
A funny and useful example of using LLMs to get different expert perspectives is making IQ bell curve memes for concepts you’re trying to learn. 4o is decent at making them although you may get better results from copy-pasting in a description of what they are first (or, click the button below!).
Here I let 4o describe the IQ bell curve meme to give it a better understanding for when I ask it to complete the task of making one. Then I prompt it to make the meme:

Make sure you ask it make it in text, though:

Learn what matters the most by generalizing #
Use LLMs to find trends to compress together ideas. I.e. take a bunch of ideas and find a common theme that ties them all together.
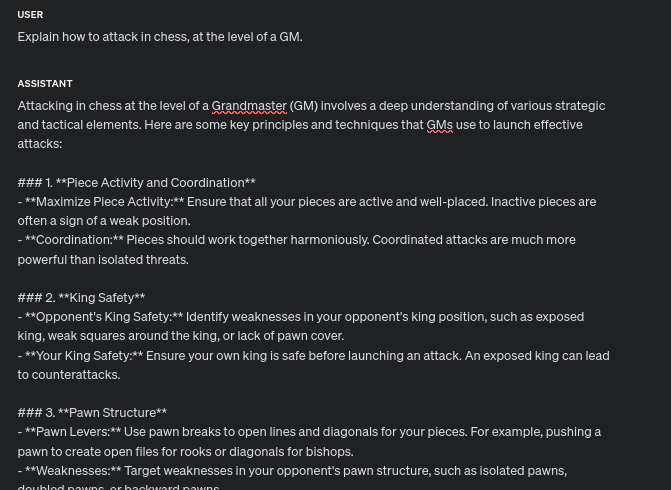

As a chess player, the pre-generalized output is kinda useful. However, the post-generalized output is incredibly strong. Personally, those two points encompass my entire attacking strategy (which is usually 60-90% of my focus in a chess game).
Learn by analogizing #
Use LLMs to get better at generalizing between domains.
[the prompt below is an extension of the chat above in the generalization section]

Etymology #
Understand concepts and terms better by asking about their etymology.



Find important unseen/overlooked high-level fundamentals #
Find common terms at a higher skill level of your field than where you’re currently at. Then learn/understand those terms/concepts. They are usually fundamentals (which means they have massive ripple effects everywhere, and have disproportionately high impact when you spend time to improve them) and if you think they dont matter (or skim over them because you don’t understand them), you are probably overlooking them and missing out on something important – which is a great opportunity to improve
Here’s a SWE example. If you don’t understand something they are talking about, it’s probably something worth putting a decent chunk of time into understanding.


It might take some prompting to get an output with relevant higher level fundamentals that will be useful for you to learn. However it’s definitely worth it when you find some. This can be done for any industry or domain.
You can also do this IRL by listening to experts talk to each other (videos/podcasts, irl conversations, etc), and learning/solidifying the concepts you don’t understand. If a chess GM talks about how their opponent has a dark square weaknesses, figure out what that means, why it’s important, and how to use that concept in your own games.
Find novel useful concepts #
This takes a significant amount of work. The model is trained on 95% slop and will generally just output slop. I don’t have a specific example prompt here, but whenever I’ve been able to get LLMs to output new, useful concepts, it has been tremendously useful.
Create flashcards and quizzes #
Self testing is a great way to learn certain concepts. Flashcards can be extremely effective in the right circumstances. LLMs will automatically turn your notes into flashcards, and automatically turn the flashcards into a format you can copy and paste into quizlet.
You can just take all of your notes, dump them into gpt4, and say “Find important concepts that may be on a test, or may be important irl. Write them down in detail. Then make flashcards, consisting of a front side and a back side, that will most effectively help me learn the content in these notes. Then finally turn them into a quizlet importable format” and it will do it.
It will also turn your notes into practice tests you can use to test yourself.
Abstraction #
Explain a concept at different levels of abstraction

Example prompt: “Explain the concept of {x} at different levels of abstraction, from high level/abstract to low level/implementation”
Using LLMs to make things #
Efficiently programming multifile projects #
LLMs are pretty powerful when they’re working with a project split up into multiple files. They’re great with simple files, even if there are many of them.
Here’s my custom setup that makes making/editing multi file projects easy. You can steal it or make your own (making LLM tools is a great habit to get into)
- custom system prompt
- custom (open source) cmd line tools
First I click a bookmark that takes me to gpt4o with my custom system prompt and temp set to 0.

Then I tell the AI what I want it to build, or I copy and paste the files in my current project and tell it what changes I want.
To make copying all of my files easy, I made a cmd line tool to take select files, format them into a prompt, and automatically copy them to my clipboard.

The LLM then outputs a response containing multiple files.
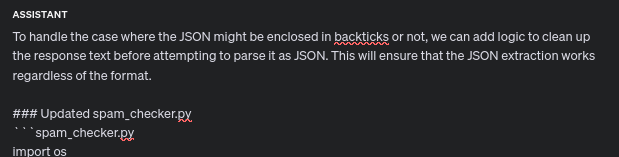
Here’s where the magic of the tools comes in.
I copy its entire response, write ‘mkfiles’, and my tools automatically create or update every single file that was in the AI’s response. Even ones in directories.

Once it automatically creates all of the files, I run them, copy/paste in the error + any changes I want, it outputs the updated files, I run mkfiles again to instantly update the codebase, run it again, repeat.
Here are my custom tools, feel free to download/install them or use as inspiration to make your own:
AI compilation vs AI generation #
LLMs become EXTREMELY powerful the more relevant data you’re able to give them. The more relevant data you stuff into their context window in advance of your request, the better. This can include content retrieved from RAGs on the fly, data dumped in as text beforehand, or even data you make them generate (similar to the sections above on calculation/thinking window).
LLMs are generally garbage at generating content from nothing. However, they excel at taking gargantuan amounts of existing data and compiling it into new forms.
- I sometimes do this for when I need to write large documents for my job and client companies. I built a tool to take large amounts of data about a company (powerpoints, spreadsheets, pdfs, word docs) + the requirements of the form they were applying, and use an LLM to create huge self-coherent documents out of it. You can get LLMs to make huge grants, docs, guides, etc with pretty high quality using this method.
AI generation is huge, but typically most applications don’t use much input data. AI compilation seems pretty unexplored compared to AI generation and one should keep it in mind as a tool that may potentially help solve future problems (having a solution in search of a problem is an antipattern)
JS Bookmarklets #
If you make a bookmark with the url “javascript:{your script}”, it will run {your script} every time you click it. LLMs are decent at writing these.
You can use this to make custom reader modes for articles, a button to skip download wait times on a site you visit a lot, etc. Not always the easiest thing in the world in my experience, though. As always it helps to give the LLM any relevant portions of the HTML before asking it to write the bookmarklet.
Prompt: Just ask the AI to make you a bookmarklet for some JS.
Code ‘diffusion’ #
LLMs can write very complex code, but only if they ‘diffuse’ towards it. LLMs will not write extremely complex applications off the bat, but can be made to write a first simple feature-minimal draft, then iteratively add features.
Experiment: Making a program, diffusion vs one-shot #
First, we’ll try to make a complicated program using the diffusion method, then we’ll try the exact same program with the default one-shot method.
Diffusion method #










Clicking on a level now shows this. There is also a class for the random bot that we asked for. However, there is no way for the user to remove pieces (I should probably have had the model brainstorm all necessary features first, it forgot to add this!) but luckily I can just ask it to implement it
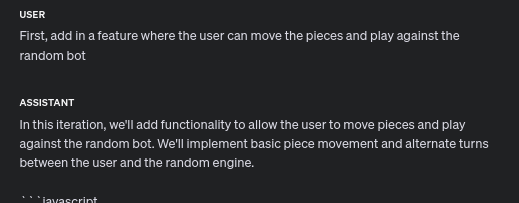

And it works! Although uh, the bot can move anywhere, and can also move my pieces sometimes. Oh well, we’re diffusing closer towards a program we want! We can always ask it to modify this later.

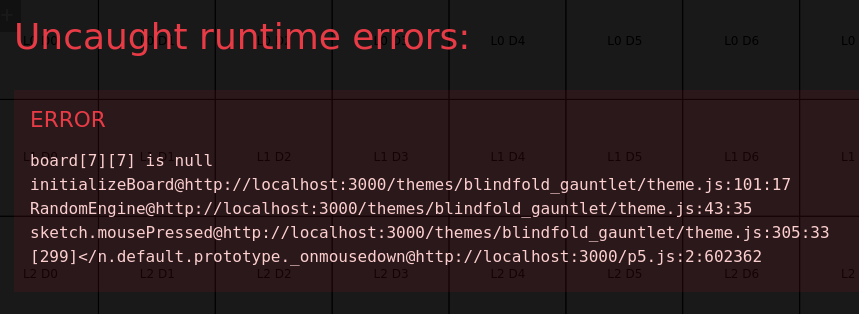
Uh oh. I’ll ask the model to fix this before the next iterations.

It worked!

Next iteration


Next iteration

Last iteration


This was supposed to be the final iteration, but GPT decided to add more iterations, I suppose because sama wasn’t done draining my wallet just yet:



Still lets me make illegal moves, but I can’t move pieces from one simul board to another. So that’s nice. There are still more changes to make, but this is a great starting point for the program.
One-shot method #
Let’s see what happens when I try to get GPT to make it in one shot, rather than using this diffusion method.
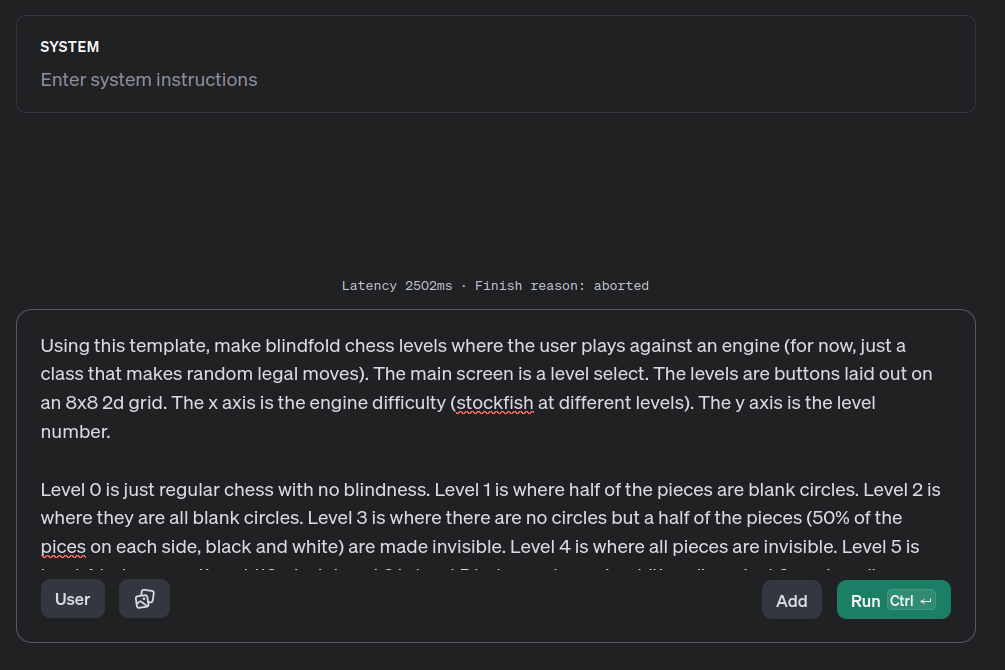
Here we go…
…and, it’s lazy.
Ok, well, let’s try to make it work, and ask the LLM to complete the code. This is now just doing diffusion, essentially.

We can continue diffusing from here. Clearly one shot alone isn’t enough. This may in fact produce a great output! However, there is a huge glaring flaw that exists in this second diffusion method. We cannot test the code as we go. Meaning, the model has the potential to ‘drift’ further and further away from a program that actually works. With the first diffusion method, there was only one error and it was quickly/easily corrected, possibly because the ‘delta’ between the previous iteration’s working program and the current iteration’s erroneous program was extremely small.
Diffusion conclusion #
This method could definitely be optimized and could easily be automated. Not 100%, since a human still needs to do testing to uncover errors, but at least 90%, to the point where you could press a button and the next iteration pops up on the screen for you to test.
General LLM Optimizations #
Restart chat after mistakes #
Starting a new chat can improve the model output. The model is a token predictor. if the past tokens are full of you telling the model it made mistakes, it may bias the model towards predicting that it will continue to make mistakes, since that is the most likely completion of the text. This is not exactly how LLMs work, but is close enough to function similarly. So, when the model makes mistake after mistake after mistake, deleting the existing chat and starting over usually will improve results.
- Asking for a model to give a confidence level will make it less rigid.
Make it calculate #
If you want better answers, make it calculate.
Treat the model’s outputs like answers given from intuition with no calculation/thinking, rather than calculated thought-out answers. I.e, unless you make it think, the LLM’s responses are guesses, it’s just super good at guessing without thinking. LLM’s are extremely smart and put 0 thought into their answers. They’re mostly intuition, and make moves like a drunk chess master that could beat you 999,999 times out of 1MM (Elo is log scale of winning chances).
So, if you want better answers, make it calculate. How many sides are in a shape? It doesn’t have a good intuition for this, but if you make it think – for example, by adding emojis to each side of the shape, and then having it list the emojis, and then having it count the emojis, it will properly count the amount of shapes. Intuition applied over steps is calculation. If you want an LLM to calculate, give it a procedure. The classic example is “think step by step” but there are many other interesting ways to do this. One I commonly use, especially for writing code or large documents, is to ask for brainstorming/an outline first.
The more verbal space you give the model to think, generally, the better the output will generally be. This is calculation (same as above). Some ways to do this are to ask for outlines, plans, brainstorms, etc before asking the model to give you its answer to your question. This tremendously improves performance.
- Get prompt for program -> make an LLM break it up into iterations: start from the simplest minimal-feature program -> have another LLM implement the first feature -> have another LLM add the first feature -> have a new LLM add the next feature -> continue (Disclaimer: I have not tested this, but it is similar to how I have LLMs write complex code)
Temperature=0 #
Set temp to 0 for situations where you want less error (usually coding)
Useful tools #
Globe Explorer #
- Very powerful tool for getting an overview of anything
- Useful for quickly mapping out convoluted/complicated domains when you can’t find a great overview of what is/isnt important
- Examples include regulatory and compliance, and getting a birds eye view of a niche or industry
- Free plans exist, but strongest mode has a free trial iirc


Perplexity #
- Extremely strong search engine for finding very relevant searches, study statistics, specific figures, etc. My goto for answering specific queries whose answers are buried deep in the internet.
Semantic DB Searches #
- Great for finding relevant data when you need to search based on the meaning of your words
- Search for relevant words, phrases, or sometimes even ask questions
- Pubmedisearch
- Arxiv semantic search
Write custom tools #
- Writing custom tools that use of LLMs can be tremendously useful. For example I use a custom toolset that has saved me hours doing research on certain topics by automatically scraping hundreds of documents (from webpages, youtube playlists, pubmed, arxiv, etc), having an LLM use each one to answer my prompt, then having some other LLMs recursively merge all of them together into one final report
Platforms #
- Platform.openai.com
- Openai’s API based playground
- Has a nice chat interface with a lot of functionality, including system prompts, setting temperature, max tokens, and more. Allows access to easy fine-tuning of models.
- Sometimes you can get slightly earlier access to new models on here
- You can save presets of your settings (temperature, prompts, etc) and bookmark them for quick access to your favorite model configuration (personally I have a bookmark to GPT 4o, 4096 token output, temp=1)
- Pay per token (4o is $5 per million input tokens and $15 per million output)
- Can break/glitch out sometimes. If this happens, clear storage for platform.openai.com in your settings or press F12, go to application storage, and delete local storage, then re-log in.
- AWS Bedrock
- Has a large number of models including all Claude models, stable diffusion, embedding models from AZ, llama, etc (does not include gpts).
- Has a nice chat interface with a lot of features, although no stop feature, which can be a pain sometimes


Quick LaTeX Renderer #
- Not an AI tool, but useful for when bedrock models or platform.openai.com output a response in LaTeX.
- Not sure about other LLMs, but GPT4 for certain problems will output LaTeX no matter how much effort you put into asking it not to. Even if you give it examples of latex, and tell it not to use it, it will still output it as if it didn’t understand your tokens the way you understood them. It sort of reminds me of glitch tokens.

Not useful but fun #
Set GPT’s temp high for schizo mode

Also, trying to get the LLM to maximize outputs that are:
- funny
- unexpected
- novel
- innovative
Conclusion #
Get really good at LLMs, get smarter, and build things people want
SWE is about building things, not just writing code. Building things with LLM is like a different kind of programming that is much higher leverage. It also has an Elo ladder you can climb. Get good at building things with llms to get good at creating gargantuan amounts of value for yourself and others. Treat LLMs like a new programming language that just came out and is 10x more powerful. There is an endless amount of work to be done in the domain of building things ppl want




